
Introduction
Edge Artificial Intelligence (Edge AI) is employed in various computer vision applications, such as digital assistants and self-driving cars, where quick responses are essential and even a small latency could have significant consequences. Thus, speeding up an edge device's processing time is vital. Internet of Things (IoT) devices have somewhat addressed this issue by processing data closer to the data generation source, a mechanism known as "Edge Computing." NVIDIA Jetson Nano and Raspberry Pi 3B are affordable, commonly used embedded SoM (System on Module) devices for edge computing, AI, and machine learning. They integrate GPU, CPU, DRAM, and flash storage on a compact platform. By measuring application workload performance and identifying areas of inefficient programming, performance bottlenecks, and memory I/O leaks, performance can be further enhanced programmatically. This project employs three methods to profile edge devices (e.g., NVIDIA Jetson embedded GPU) -- NVIDIA Nsight Systems, NVPROF, and tegrastats GUI version jtop to analyze a sample program. Various optimization techniques have been applied and scrutinized to observe performance improvements. Additionally, a performance comparison of diverse benchmarking models and two edge devices has been conducted to determine the best models for their respective hardware architectures.
Analysis
Environmental Setup
Nvidia Nsight Tools
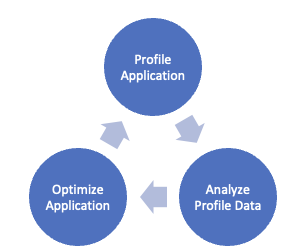
Profiling involves an iterative process of analyzing profile data, optimizing the application, and profiling the application again to verify if the desired behavior is achieved (Fig 1a). This process continues until the target performance is reached.
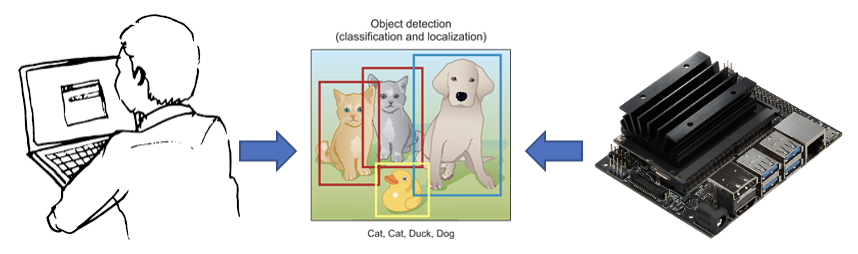
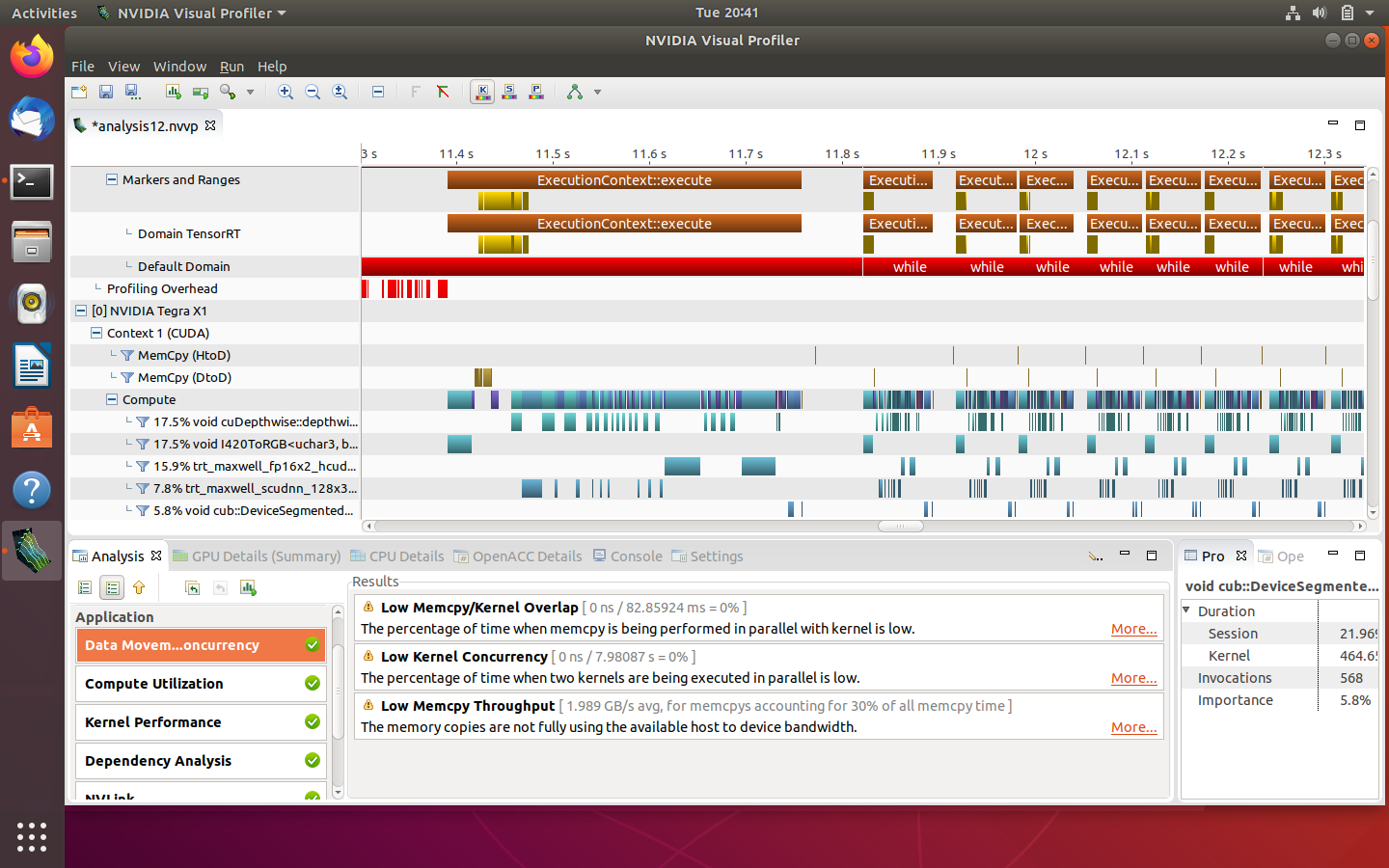
Many edge device deep learning applications are based on ML frameworks written in Python. Although there are numerous Python-based profiling tools available, such as cProfile, PySpy, VizTracer, PyInstrument, and Yappi, none of these tools can profile code running on a GPU for Python. However, NVIDIA's Nsight Tools (comprising Nsight System and Nsight Compute/Graphics) can perform both system and kernel-level analysis for Python programs. Edge profiling can be time-consuming and cumbersome, generating a vast amount of complex data. The reliance on a separate host device to perform profiling on the target edge device adds to the complexity.
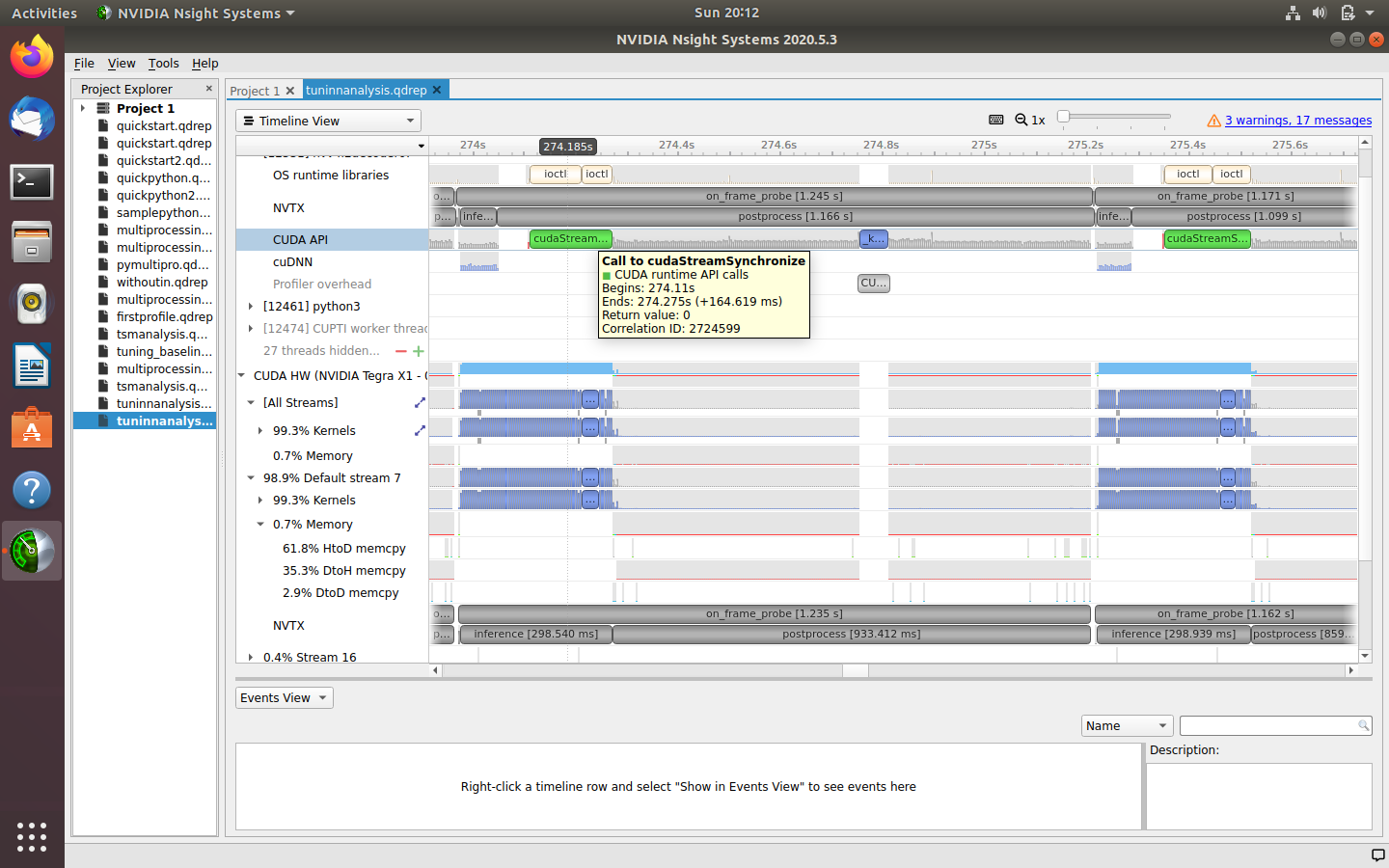
A sample deep learning model is profiled using NVIDIA Jetson Nano (4GB RAM) as the target device, where the application to be profiled is running. It comprises an NVIDIA Maxwell GPU with 128 NVIDIA CUDA Cores and a quad-core ARM Cortex-A57 MPCore CPU processor. A virtual machine of Ubuntu 18.04 installed on a MacBook Pro is used as the host device, where visual profiling tools such as Nvidia Nsight Systems and Visual Profiler have been set up. Detailed steps for profiling with Nsight Systems can be found under my GitHub link (NsightSystems) and with
Visual Profiler under my GitHub link (VisualProfiler). First, Nsight Systems is used to perform the initial system-level analysis to eliminate system-level bottlenecks, such as unnecessary data transfers, and improve system-level parallelism. Once satisfied with the performance, Nsight Compute/Graphics/Visual Profiler can be used to perform deeper kernel-level analysis to analyze each CUDA thread.
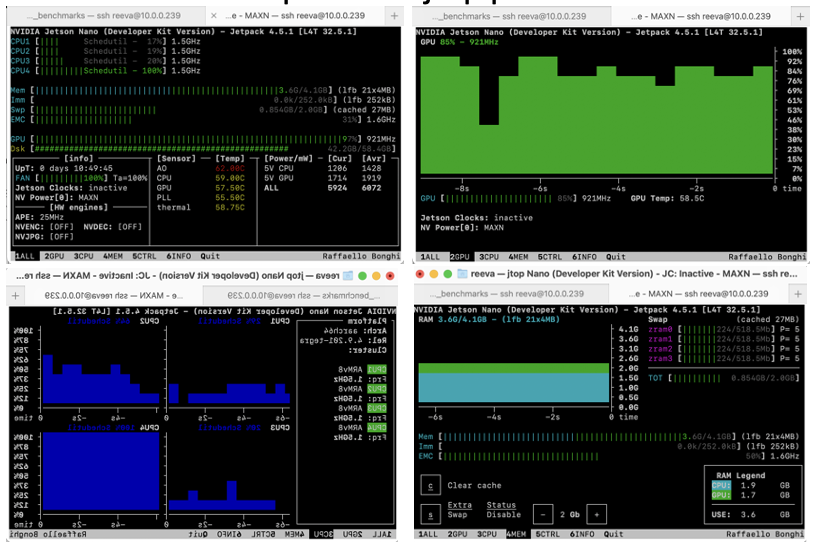
Jetson stats can also be utilized to visualize output, as it combines both tegrastats and NVP model into a GUI to profile and control Jetson. Its most popular tool is jtop, which provides a summary of Jetson CPU and GPU utilization, power consumption, and thermal dissipation in a coarse time scale. It can run directly on the Jetson device. In contrast, Nsight Systems offers individual activities across a fine time scale, making it a better tool for performance optimization.
Implementation
Sample edge AI program
NVIDIA's SSD300 (Link) is an object detection model trained on the COCO dataset. The model's output consists of bounding boxes with probabilities for 81 object classes. The profiling and optimization of a video inferencing pipeline program based on the SSD300 model are demonstrated here. The code has four essential parts: buffer to image tensor (converting video frames into PyTorch tensors), preprocess (scaling 0-255 RGB pixel values to -1 to +1 float values), detector (running the SSD300 model), and postprocess (converting model output into bounding boxes).
Tracing with Nsight System and Optimization
Upon running the baseline program on the edge device (Jetson Nano used here), an FPS of 1.09 was achieved. After analyzing the qdrep file, it was concluded that CPU usage is very high, GPU is used only during inference, and constant memory transfers result from continuous synchronization between CPU and GPU.
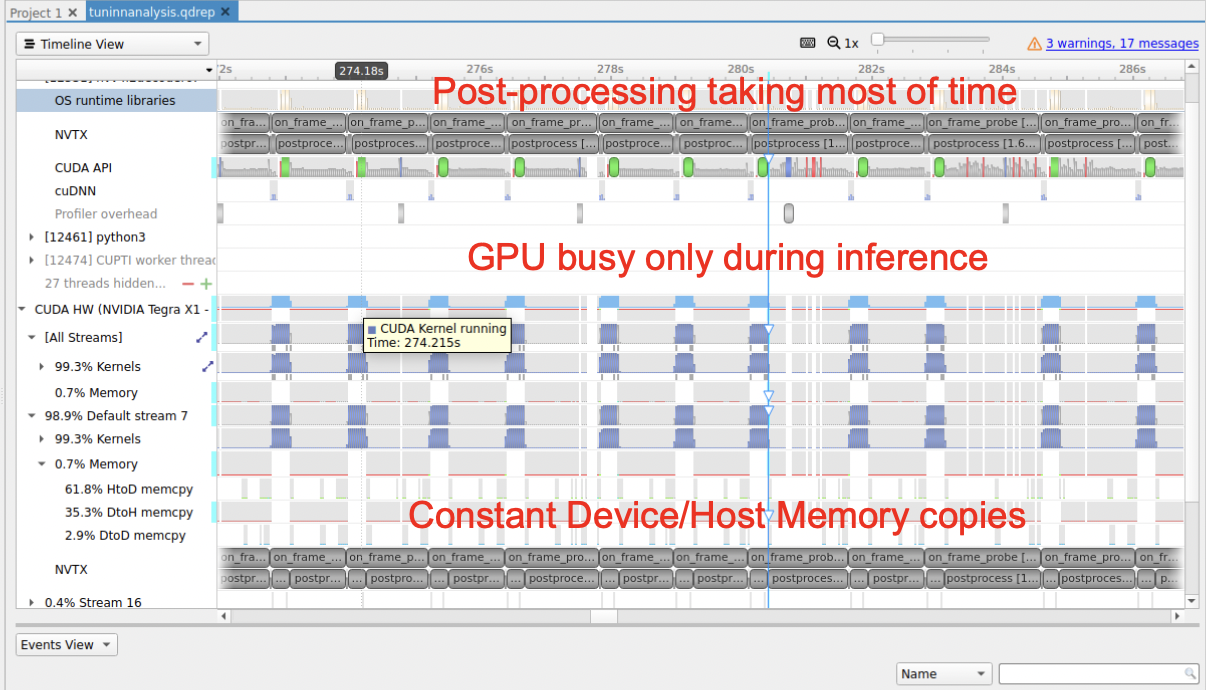
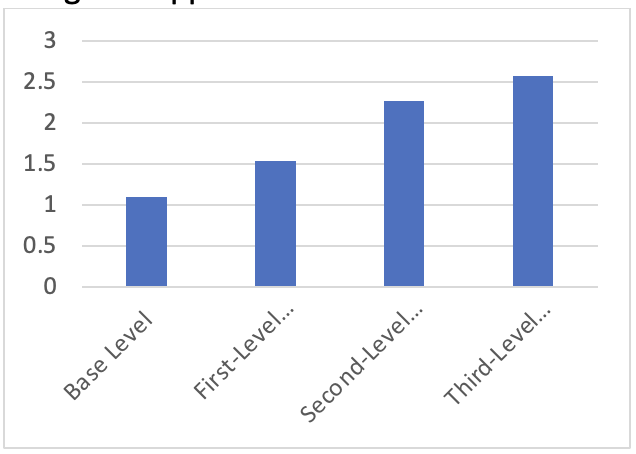
First level Optimization – The tensors (in the postprocessing function) were accessed on GPU and the computation was performed on CPU. So, when these tensors were moved to CPU with “.cpu()”, FPS increased to 1.53 (40% improvement). Second level optimization – Here, all the preprocessing and postprocessing parts of the application is moved to GPU and the FPS increased to 2.27 (48% improvement) without the profiling overhead. Third level optimization - In this step of batch processing i.e., multiple frames are sent to the neural network. By this, it was observed that the FPS increased to 2.57 (13% improvement). Fourth level optimization – In this step, half-precision data was adopted to check if it improves the performance by reducing memory usage of neural network. Reducing to fp16 cuts down the size of weights of neural network models by half but reduces the accuracy by a minor amount. However, it was observed that the FPS got dropped to 1.20. The performance improvement can be seen from the Fig 3 Right. Overall, there was an improvement of 68%. All the profile files (qdrep) after each level of optimization can be found under my GitHub link.
Other Benchmark Models
To test more on the dependency of data precision with performance, I tested the other benchmark models with data precision of fp32 and fp16, and the results are as follows:
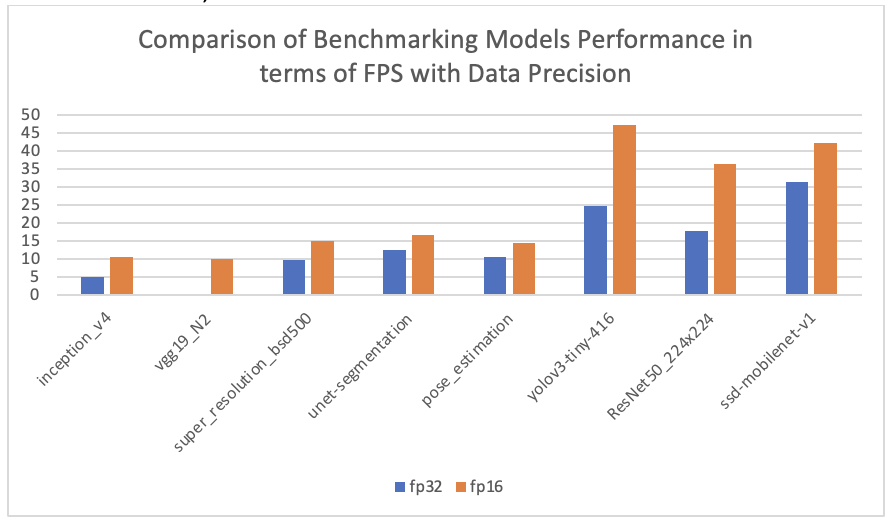
Findings: The above deep-learning models were executed on Jetson Nano with data precision fp32 and fp16. Reducing to fp16 cuts down the size of weights of neural network models by half but reduces the accuracy by a minor amount. The rate of variation in performance with half-precision data is dependent on both the application’s model architecture as well as on the hardware specifications (un derstood from table and observation above). The background processes for some models was observed further closely (difference in processing time of different threads due to variation in data precision) with Nsight systems whose qdrep files can be found under my GitHub link(BenchmarkModels).
Hardware Platform: Raspberry pi vs Jetson Nano
To evaluate application’s performance dependency on hardware specifications, I executed the same applications both on Jetson Nano and Raspberry Pi 3B. The results can be found in figure 5.
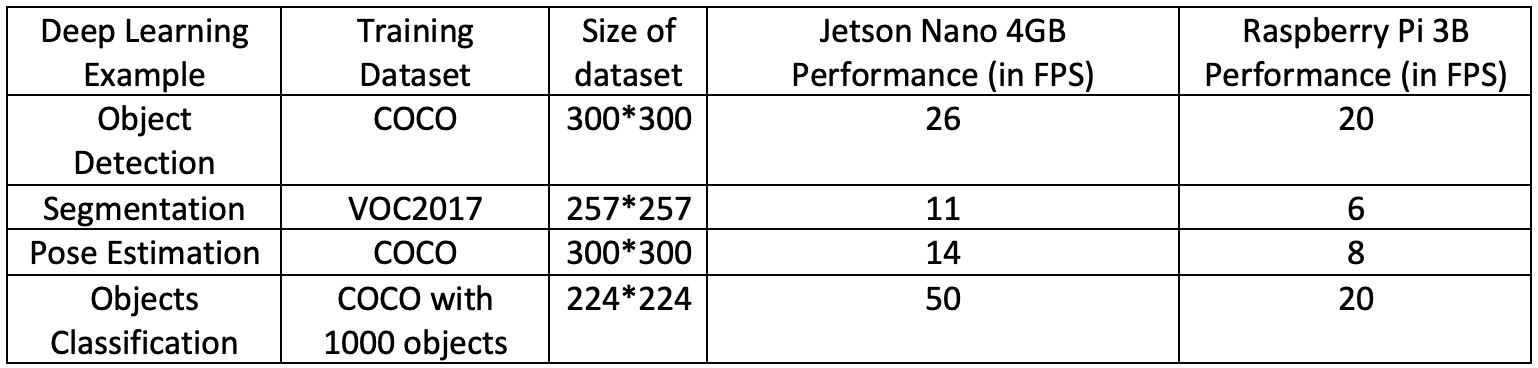
Findings: The major performance gap between the 2 edge devices is the availability of GPU delegates in Jetson Nano (not present in Raspberry Pi) which TensorFlow Lite deploys at the time of execution. The AI performance of Jetson Nano board is rated 472 GFLOPs which is just 21.4 in case of Raspberry Pi 3B. While the Jetson Nano board consists of 128-core NVIDIA Maxwell GPU architecture and a 4GB LPDDR4 RAM, Raspberry Pi has a 1GB RAM and runs on CPU mostly. The Raspberry Pi 3B comes at $35 whereas the Jetson Nano is $108. So, there is a tradeoff between price and performance.
Use Case
Based on the comparison of various deep-learning models, I selected tiny-yolo as the object-detection application for my autonomous home surveillance robot “Oni”, which uses edge AI to autonomously move around the home and monitor things and send alerts when it detects emergencies or problems (e.g.: fall detection, intrusion detection etc).
Conclusion
In conclusion, this study explored the application of Edge AI, focusing on profiling and optimizing edge devices for improved performance in computer vision applications. By analyzing and optimizing a sample program, significant performance improvements were achieved through iterative optimization processes. Various benchmark models were tested to understand the dependency of data precision on performance, demonstrating that both the application's model architecture and hardware specifications play crucial roles in determining performance levels.
A comparison between Raspberry Pi 3B and Jetson Nano demonstrated that there is a trade-off between price and performance when choosing an edge device for AI applications. Jetson Nano, with its more powerful GPU architecture and larger RAM, outperformed Raspberry Pi 3B, making it a more suitable choice for applications requiring higher performance.
By selecting tiny-yolo as the object-detection application, an autonomous home surveillance robot, "Oni," was developed. This robot leverages edge AI to autonomously monitor its surroundings and sends alerts when detecting emergencies or problems. The insights gained from this study can be useful for developers and researchers working on edge AI applications, as well as for manufacturers aiming to create better-performing and more efficient edge devices.